

Avec la prolifération de l'énergie solaire connectée au réseau - qu'il s'agisse de quelques grands systèmes à l'échelle du service public ou de milliers de petits systèmes derrière le compteur - les services publics sont aux prises avec l'intégration de ces ressources de production d'énergie distribuées et variables. Dans les trois prochains billets de blog, nous partagerons certaines méthodes et idées liées à la modélisation des " parcs " photovoltaïques, c'est-à-dire la capacité globale d'un groupe arbitraire de systèmes photovoltaïques sur le territoire d'un service public ou d'une organisation internationale de normalisation, et nous montrerons comment les services publics peuvent utiliser la modélisation des parcs solaires pour mieux intégrer le solaire dans leurs systèmes de distribution.
Aujourd'hui, dans la première partie de notre série, nous allons décrire comment prendre en compte les parcs photovoltaïques distribués qui présentent une variété de configurations de conception sur un vaste territoire géographique. Ces informations peuvent être utilisées par les planificateurs des services publics pour maintenir la fiabilité du réseau à long terme en aidant à anticiper les changements futurs dans la forme de la charge du service public, les nouveaux types de ressources qui seront nécessaires et les modifications du flux d'énergie sur les circuits de transmission et de distribution.
Dans les prochains articles, nous examinerons données à haute fréquence (résolutions temporelles jusqu'à 60 secondes), et comment ces données haute fréquence peuvent être utilisées pour évaluer l'économie de la capacité de régulation (le coût de la régulation de la variabilité PV).
Pourquoi les profils de production PV varient-ils ?
Les planificateurs ont besoin de profils solaires précis et défendables qui représentent la production attendue d'un ensemble large et diversifié de générateurs solaires. Les ressources solaires diffèrent du gaz, du charbon et d'autres ressources parce qu'elles ne sont pas réparties, mais ont des modèles de production basés sur l'irradiation disponible à leur emplacement et les attributs du système tel qu'il est construit (inclinaison, azimut, ombrage, etc.).
La figure 1, ci-dessous, illustre le défi que représente le calcul des profils solaires à utiliser dans les études de planification des services publics. Ce graphique représente les profils de production quotidiens de cinq systèmes PV fixes sur un même site. Chaque système PV utilise un matériel identique, mais diffère par ses angles d'inclinaison et d'azimut, ce qui donne des profils solaires uniques. Les planificateurs doivent se demander : " Quelle courbe dois-je utiliser ? Ou faut-il les combiner en une seule courbe ? Et si oui, comment les combiner ?"
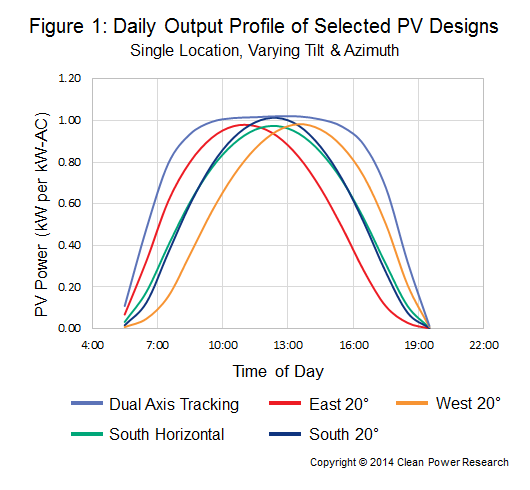
Mélange de configurations de conception PV
Clean Power Research a aidé plusieurs services publics à répondre à ce genre de questions pour modéliser de grands parcs solaires. Dans la méthode la plus simple, la production PV mesurée est extraite de tous les systèmes du parc photovoltaïque et additionnée pour obtenir le profil global. Mais que faire si les données ne sont pas disponibles ? Par exemple, certains systèmes PV sont connectés derrière le compteur et seules les charges nettes sont disponibles. Dans d'autres cas, la capacité PV est prévue dans une région, mais l'échantillon de systèmes existants est trop petit pour établir un bon profil représentatif.
Dans de nombreux cas, les entreprises de services publics disposent d'un bon ensemble de spécifications de systèmes dans lequel elles peuvent puiser. Ces données peuvent provenir de PowerClerk®, ou d'une base de données interne des systèmes installés. Les données peuvent avoir été collectées au cours du traitement des incitations ou lors de l'évaluation des demandes d'interconnexion. Ou encore, des données provenant de services publics ou d'États voisins pourraient être utilisées pour déterminer la composition d'un parc. Cette composition pourrait ressembler à la figure 2, qui montre la répartition des grands systèmes commerciaux d'une région.
Comme le suggère la figure, la capacité installée varie selon l'angle d'azimut (est, sud, ouest, etc.) et l'angle d'inclinaison (0 degré, 10 degrés, etc.). Dans l'élaboration des profils, il est donc nécessaire de modéliser la production photovoltaïque en tenant compte de la capacité relative de chaque configuration. En utilisant la répartition illustrée, par exemple, la capacité modélisée qui est orientée vers le sud avec un angle d'inclinaison de 20 degrés recevrait environ deux fois plus de poids que la capacité des systèmes orientés vers le sud-ouest avec un angle d'inclinaison de 5 degrés.
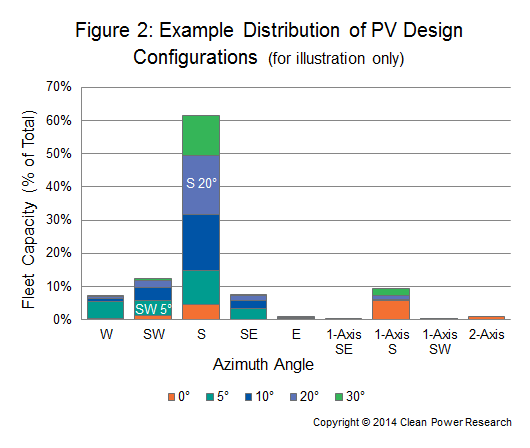
Alors que la figure 2 montre une distribution pour les grands systèmes commerciaux, d'autres parcs se présenteraient différemment. Par exemple, l'analyse pourrait montrer que les systèmes résidentiels et les petits systèmes commerciaux n'ont pas de système de suivi et peuvent avoir plus de capacité en dehors de l'orientation sud. Par ailleurs, les systèmes à l'échelle des services publics pourraient avoir plus de capacité de suivi et plus de capacité fixe orientée au sud. Dans chaque cas, un échantillon approprié de conceptions de systèmes constituerait la base de l'effort de modélisation.
Mélange d'emplacements géographiques
Outre les variations d'azimut et d'inclinaison, la capacité du système est répartie sur une région géographique, et chaque emplacement présente des différences d'irradiation et de température, qui ont un impact sur la production d'énergie. Sans données mesurées, la méthode la plus simple pour modéliser la production d'énergie de chaque système serait d'utiliser les données susmentionnées collectées pendant le processus d'incitation ou d'interconnexion pour identifier l'emplacement de chaque système, et d'utiliser les données d'irradiance et de température correspondantes, telles que SolarAnywhere les données de l'année GHI typique (TGY). Par exemple, PowerClerk pourrait être utilisé pour identifier chaque système par l'adresse du client, à partir de laquelle la latitude et la longitude exactes peuvent être déterminées.
Dans certains cas, les emplacements des systèmes ne sont pas connus (par exemple, lors de l'estimation de la capacité future). Dans ce cas, la distribution géographique doit être estimée, et il existe quelques options. Une méthode de simplification peut consister à supposer que la capacité derrière le compteur est située au centroïde de chaque code postal, et que la capacité à chaque emplacement est proportionnelle à la population du code postal. La figure 3 illustre cette méthode en montrant chaque code ZIP du nord de la Floride. La population de chaque code postal détermine la capacité PV relative qui s'y trouve.
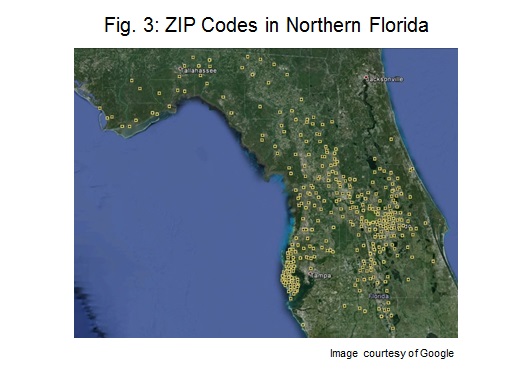
Contrairement aux ressources photovoltaïques installées chez les clients, les ressources à l'échelle des services publics ne devraient pas être situées dans des zones peuplées. Pour ces parcs, d'autres méthodes de mise à l'échelle pourraient être utilisées, comme l'inverse de la population ou des terrains disponibles.
Tout mettre en place
Supposons que nous voulions modéliser le comportement de grandes ressources PV commerciales derrière le compteur dans le nord de la Floride. Un parc représentatif pourrait être modélisé comme un groupe de systèmes à chaque emplacement. Nous utiliserions les configurations suggérées par la figure 2 (représentées par 23 systèmes distincts), et les localiserions à chaque code postal de la figure 3 (330 emplacements). Il s'agirait d'un parc représentatif de 23 systèmes x 330 emplacements = 7 590 systèmes. La capacité de chaque système correspondrait aux facteurs de pondération décrits ci-dessus.
Chaque système serait modélisé et les résultats seraient additionnés pour donner le profil du parc sur la période de modélisation. La figure 4 en est un exemple. Elle montre le résultat de la modélisation d'un parc pour une seule journée, à partir de données différentes, mais d'un processus similaire.
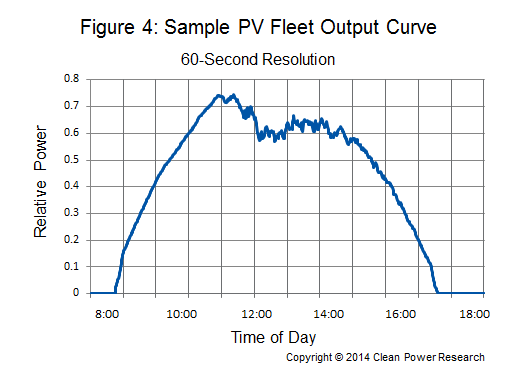
A venir...
Ce qui précède décrit de nouvelles méthodes puissantes pour créer des profils de parcs photovoltaïques, même lorsque les informations sur le parc sont limitées. Cette nouvelle capacité a un certain nombre d'applications intéressantes pour la planification et l'exploitation des services publics. Il s'agit notamment de la modélisation des charges dans des scénarios de forte pénétration (la " courbe du canard ") et de l'estimation des réserves de régulation nécessaires pour accepter le PV sur le réseau.
La semaine prochaine, nous expliquerons comment utiliser ces concepts en combinaison avec des données "haute fréquence" (données solaires par satellite avec une résolution temporelle allant jusqu'à 60 secondes), et comment cela peut aider les planificateurs de services publics.